可以让一个模型同时具备"深度推理"和"优质推理链路筛选"的能力吗?
问小白的答案是:可以。
今天,问小白研发团队要跟大家分享一个新模型:元石反思型生成式模型(Reflective Generative Model),简称 MetaStone-S1。我们将该模型与 OpenAI o3-mini 模型进行了性能对比,以此验证我们算法的先进性。
MetaStone-S1 通过元石科技提出的反思型生成范式训练得到,该技术亮点主要包括:
- 业界首次实现"Long-CoT 强化学习"和"过程评分学习"融合的范式:该范式能够让一个模型同时具备"深度推理"和"优质推理链路筛选"的能力。通过共享过程评分和策略模型的主干网络,该范式仅引入了 53M 的过程评分模型参数量。进一步地,基于 Task-specific Head 的并行预测,能够实现又快又好的文本回答效果。
- 不需要额外的过程监督标注:使用结果奖励标签监督过程评分模型,并提出基于自监督损失函数的端到端训练方法。
- 揭示了反思型生成范式的 Aha Moment、 Scaling Law:将大模型像人一样筛选优质推理过程的流程可视化,并展示新范式下大模型的智能涌现;通过拟合 1.5B~32B 的推理曲线,量化思考长度和模型性能对应的关系。
想特别说明的是,MetaStone-S1 的论文、代码、模型权重已全部开源。
与 OpenAI o3-mini 的性能对比
我们选择了包括考验模型数学推理能力的高难度"全美数学竞赛"「AIME 24、25」 和考验模型代码能力的权威测试基准「LiveCodeBench」,对于中文推理任务,我们选择了中文科学问答测试基准「C-EVAL」。所有数据集均以 Pass@1,并测试 64 次取平均作为最终评测精度。
在 low/medium 推理模式下,其对比结果如图 1 所示,我们提出的 MetaStone-S1-32B-low 性能全面超过 OpenAI o3-mini-low,并且在 medium 模式下达到了与 OpenAI o3-mini-medium 相近的水平。
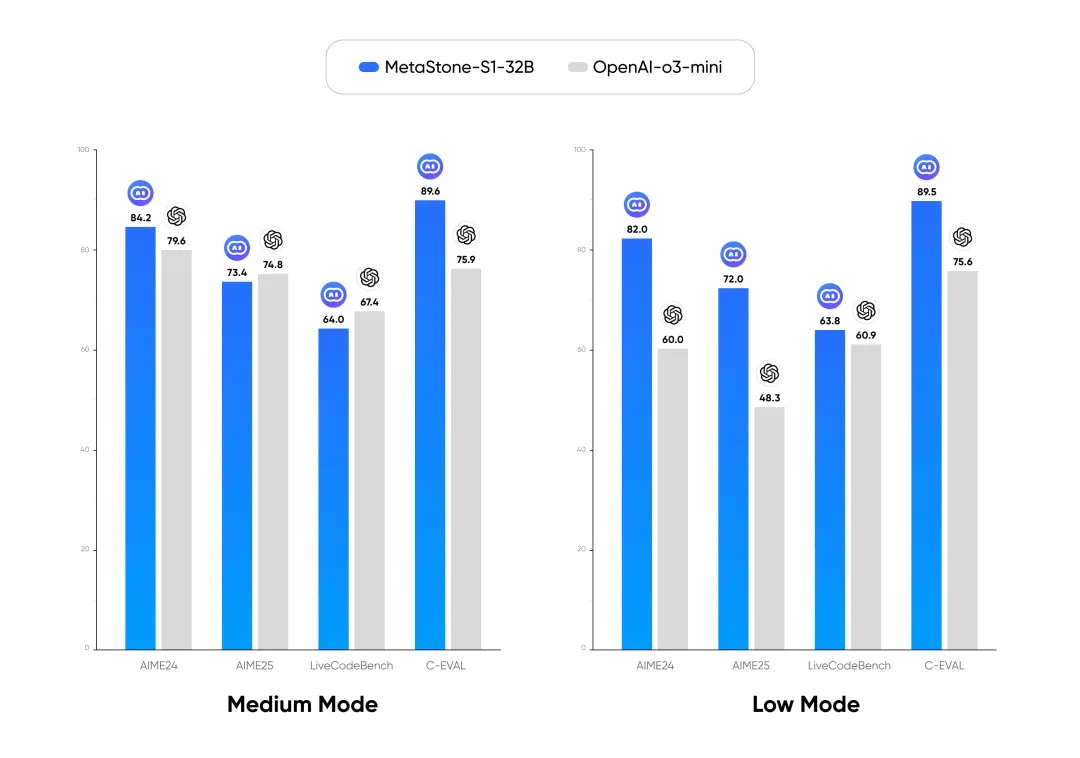
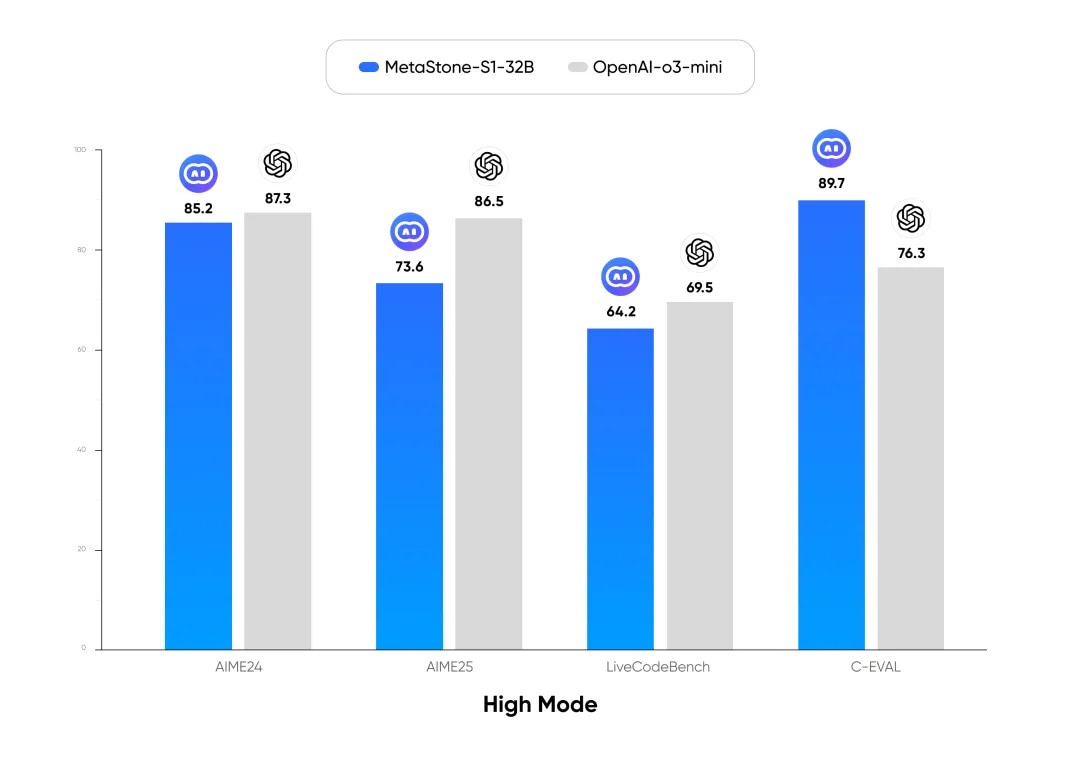
在 high 推理模式下,其对比结果如图 2 所示,MetaStone-S1-32B-high 在中文推理任务上超过了 OpenAI o3-mini-high,而在数学、代码任务上与其相比还有一定差距。这部分差距是由于本次采用较早期的基座模型(QwQ-32B)导致的,在后续算法迭代中,我们会逐步开源自研基座来进一步提升该算法的性能上限。
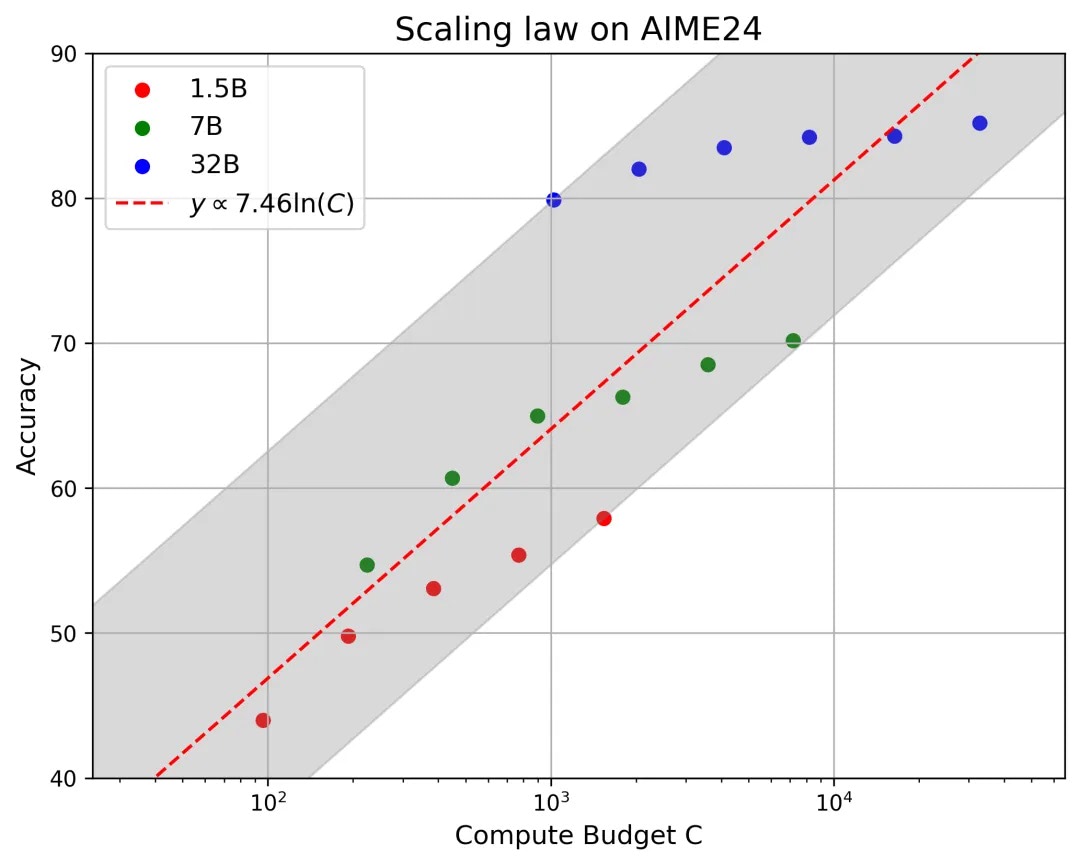
思考长度的 Scaling Law
我们提出了反思型生成范式下的 Scaling Law,即思考计算量和模型性能对应的关系,我们定义计算量 C 为模型参数量和总思考 token 数的乘积,拟合得到,即最终 TTS 精度能够随计算预算的对数而增长(具体增长比例取决于基线模型架构)。
• 思考更长
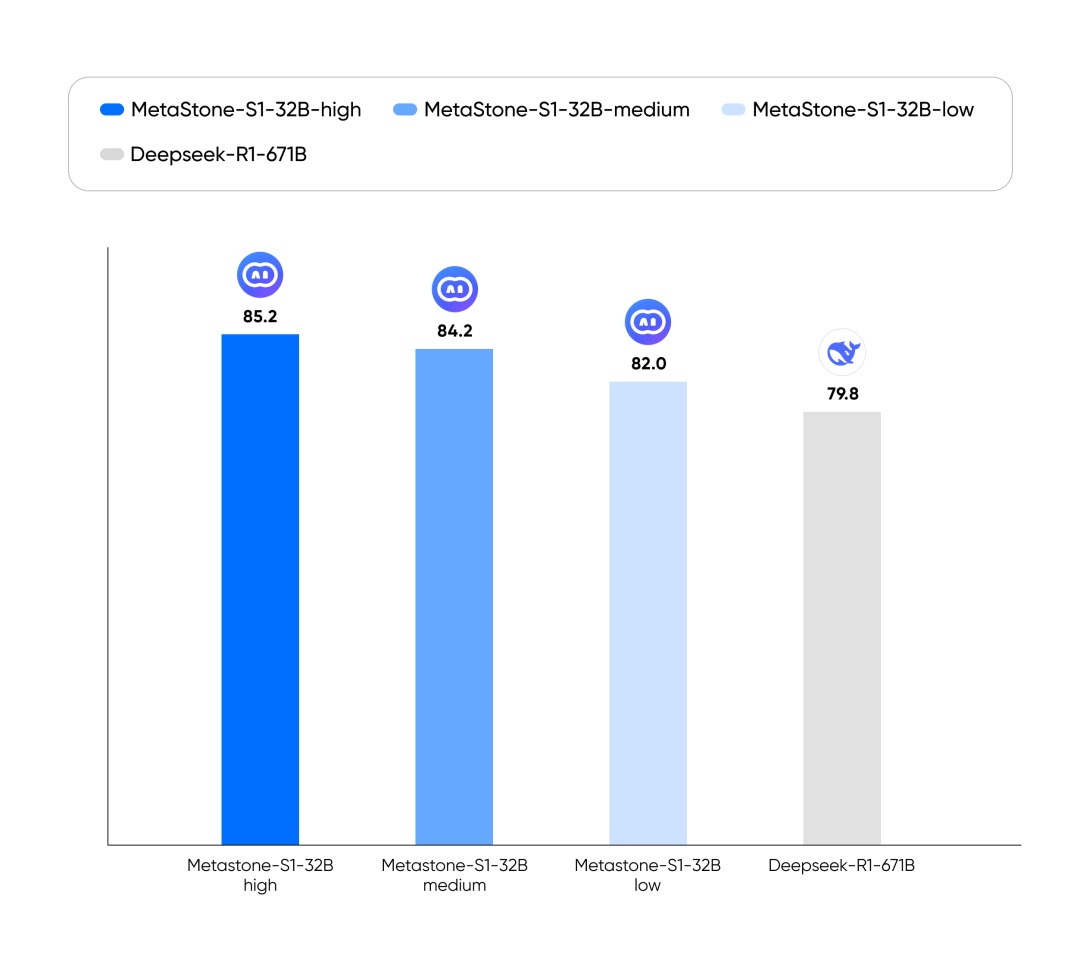
MetaStone-S1 具备业内最长思考长度,显著领先 Deepseek R1-671B-0120(与 QwQ-32B 同期发布的模型)。MetaStone-S1-low 旨在快速思考并回答用户问题;MetaStone-S1-medium 在思考长度和精度之间找到了一种平衡;MetaStone-S1-high 大幅探索了模型思考长度的上限,以获得更高的智能版本。

• 性能更高
图 5 展示了 MetaStone-S1-32B 与 DeepSeek-R1-671B 的性能对比,我们在全美数学竞赛 AIME24 上,以 32B 的参数超过了 671B 模型的性能。
• 成本更低
MetaStone-S1 相较 OpenAI o3-mini 和 Deepseek R1 具有更低的推理成本。
| 模型 | 输入 (美元/百万 tokens) | 输出 (美元/百万 tokens) |
|---|---|---|
| OpenAI o3-mini | 1.10 | 4.40 |
| Deepseek R1 | 0.55 | 2.19 |
| MetaStone-S1 | 0.28 | 1.10 |
技术细节
反思型生成范式
我们提出了一种将推理与过程评分统一的反思型生成范式。具体地说,将策略模型(policy model)与过程奖励模型(Self-supervised Process Reward Model,SPRM)共享同一个骨干网络,并在其上设计两个预测头,分别用于生成解答与对解答过程的自我评估(过程反思)。
如图 6 所示,该范式一方面支持模型在生成过程中实时进行自我反馈与 on-policy 优化,促进推理质量提升;另一方面仅依赖单一模型即可同时完成推理与过程评估,避免了对外部奖励模型的额外依赖,实现高效的一体化自监督学习。
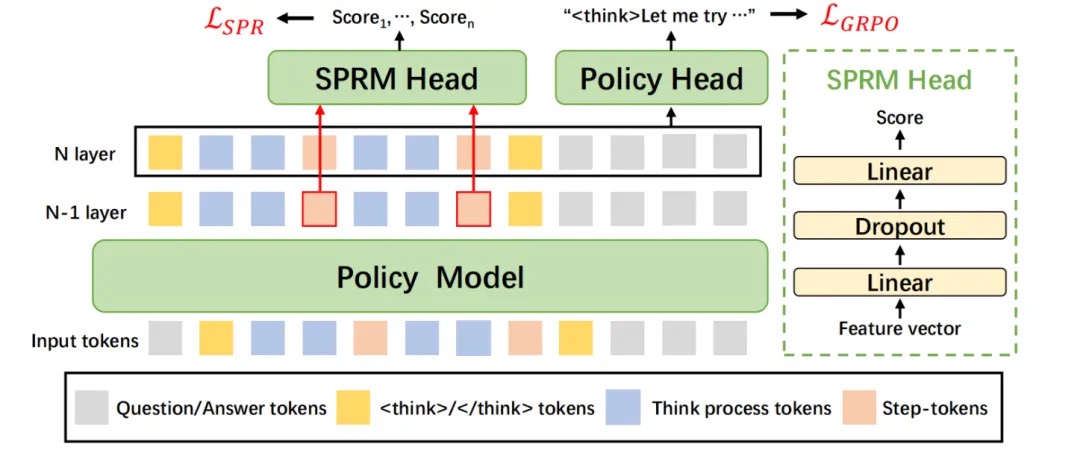
在训练阶段,我们使用联合损失同时优化策略模型和 SPRM,其中策略模型使用通用强化学习方法直接优化(如 GRPO),SPRM 则使用我们提出的 SPR loss 进行自监督优化,整体损失函数如下所示:
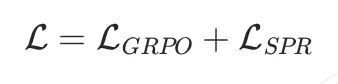
自监督的奖励模型优化方法
我们提出了一种无需步骤级标注的自监督过程奖励模型优化损失 SPR loss,如下式所示,将推理结果的正确性 作为步骤级评估的伪标签,并使用推理结果的正确性 和 SPRM 预测结果的一致性作为权重过滤不可靠的噪声标签,实现高效且低成本的过程奖励模型优化。
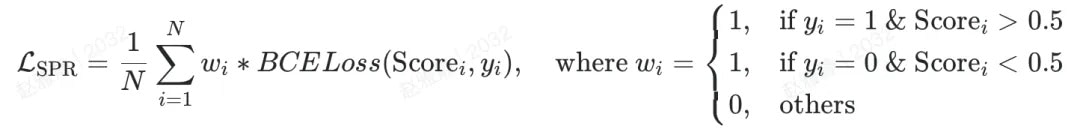
基于 SPRM 推理方法
SPRM 从设计原理上非常适合 Test Time Scaling(TTS)。如图 7 所示,在推理阶段,我们首先使用推理模型生成多个候选的思考过程 ,然后使用 SPRM 预测头对 的每个步骤打分得到 ,并计算整个推理过程的得分 。最终,我们筛选出得分最高的思考路径 ,并基于 继续使用策略模型生成完整的解答过程。
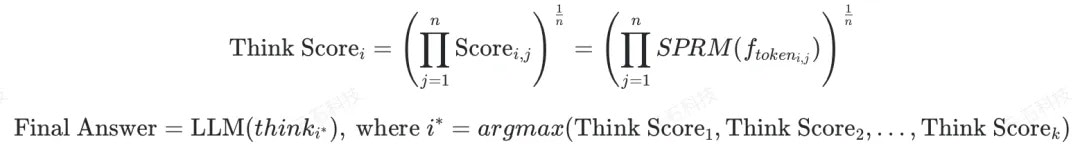
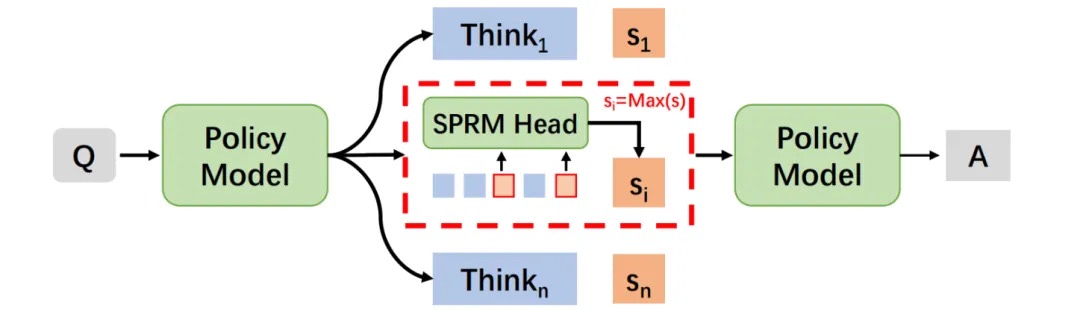
基于上述方法,我们提出了专注于推理能力优化的推理模型——MetaStone-S1;在推理阶段,通过 Rollout 调整模型生成的候选思考过程数量,我们设置了三种推理模式 MetaStone-S1-high(候选思考过程数量=32)、medium(候选思考过程数量=8)、low(候选思考过程数量=2)以实现更全面的思考或更好地平衡计算成本,从而灵活适应不同场景的推理需求。
反思型生成范式的 Aha Moment
本章节重点分享一下反思型生成范式中过程评分的可视化。
1.过程评分的可视化
下图为模型对推理过程打分的可视化结果,每个步骤基于".\n\n"符号分隔,并通过 SPRM 进行过程评分。
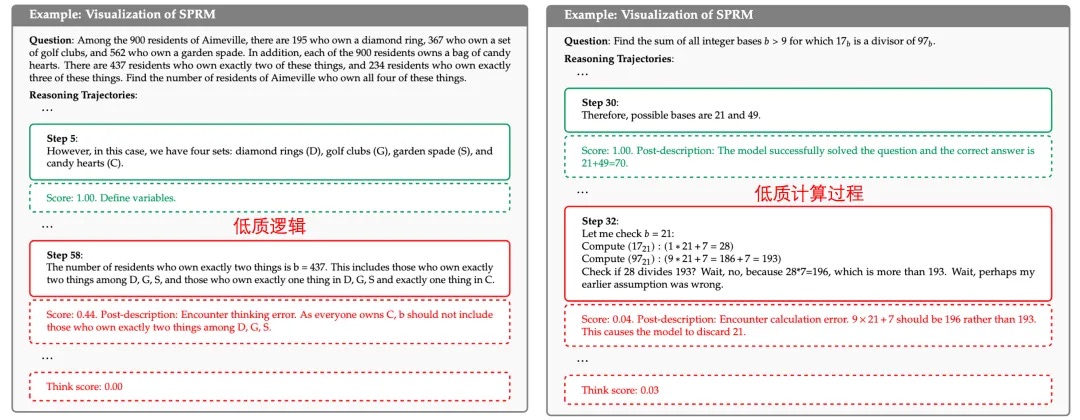
可以看到 SPRM 能够正确检测出策略模型低质推理过程,包括低质逻辑(如图 8 左侧 step58 中对 b 的逻辑错误)、低质计算过程(如图 8 右侧 step32 中的 9 * 21 + 7 = 193 的计算错误),并在对应步骤给出低分。由于 SPRM 只输出过程评分,我们在虚线框内进一步加入了后验描述(Post-description)。
2.反思型生成范式的"Aha Moment"
上述低质推理过程判断能力是如何出现的?
我们观察到了反思型生成范式在训练过程中的"Aha Moment",即对低质推理过程判断能力的涌现。如图 9 所示,SPRM 在训练初期,倾向对大部分推理步骤均学习打出高分,而在训练中间的某一时刻后,SPRM能够显著性地区分低质量的推理步骤,从而降低负样本的过程评分趋势。
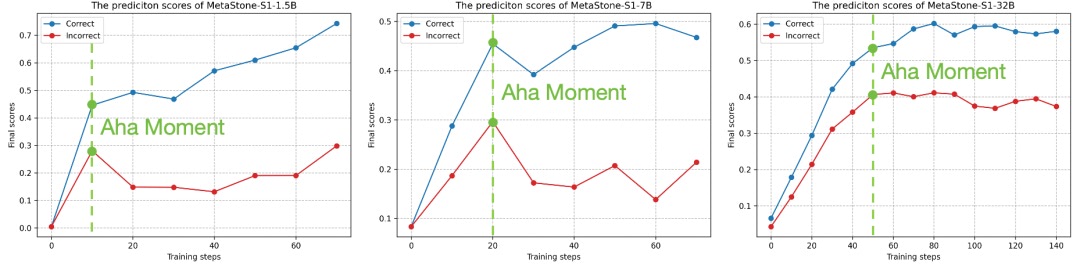
进一步,我们将 aha moment 前后对低质推理过程的评分情况进行了可视化。如图 10 所示,在 aha moment 前后,SPRM 的能力涌现能精准判断等式化简过程中的计算错误,从而给当前步骤较低的评分。

对比常规奖励模型
我们提出的自反思型生成范式以 26M 的超低参数量超过了 72B 的独立奖励模型。特别地,对于 MetaStone-S1-32B,其 SPRM 参数量也仅为 53M,远小于 72B 的独立 PRM 模型。
模型开源
目前,我们已经开源了 MetaStone-S1 系列模型,包含了 1.5B 、7B、 32B 三个尺度,希望能够为推理模型的进阶带来一条新的思路。
问小白成立的宗旨是:以最可及的方式,让先进的 AI 技术服务于最广泛的人群。未来,我们将持续推出更轻量且高效的推理模型,并以开放、共享的姿态,与开发者社区携手共建通用智能的下一个里程碑。